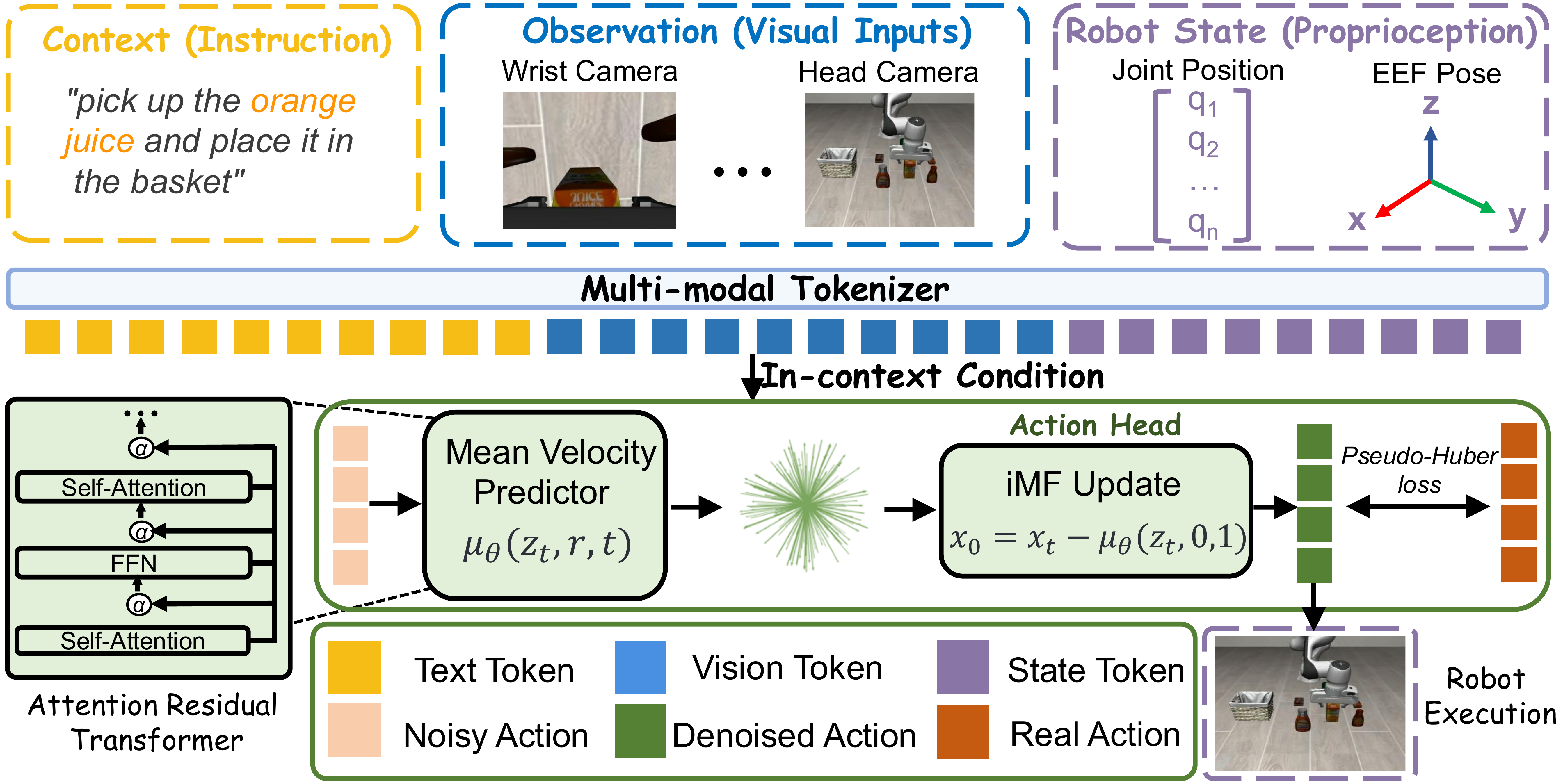
While diffusion-based VLA policies excel at modeling expressive and multimodal action distributions, their reliance on iterative sampling introduces substantial inference latency, limiting their applicability to reactive closed-loop robot manipulation. To address this challenge, we propose ReactVLA, a low-latency and lightweight Vision-Language-Action framework for reactive robot manipulation. ReactVLA integrates two complementary components: (1) an improved Mean Flow (iMF) action generator that reduces expensive multi-step diffusion sampling to a one-to-two-step generation process, and (2) Attention Residuals (AttnRes), which replace uniform residual accumulation with dynamic depth-wise feature routing to better preserve multimodal representations.
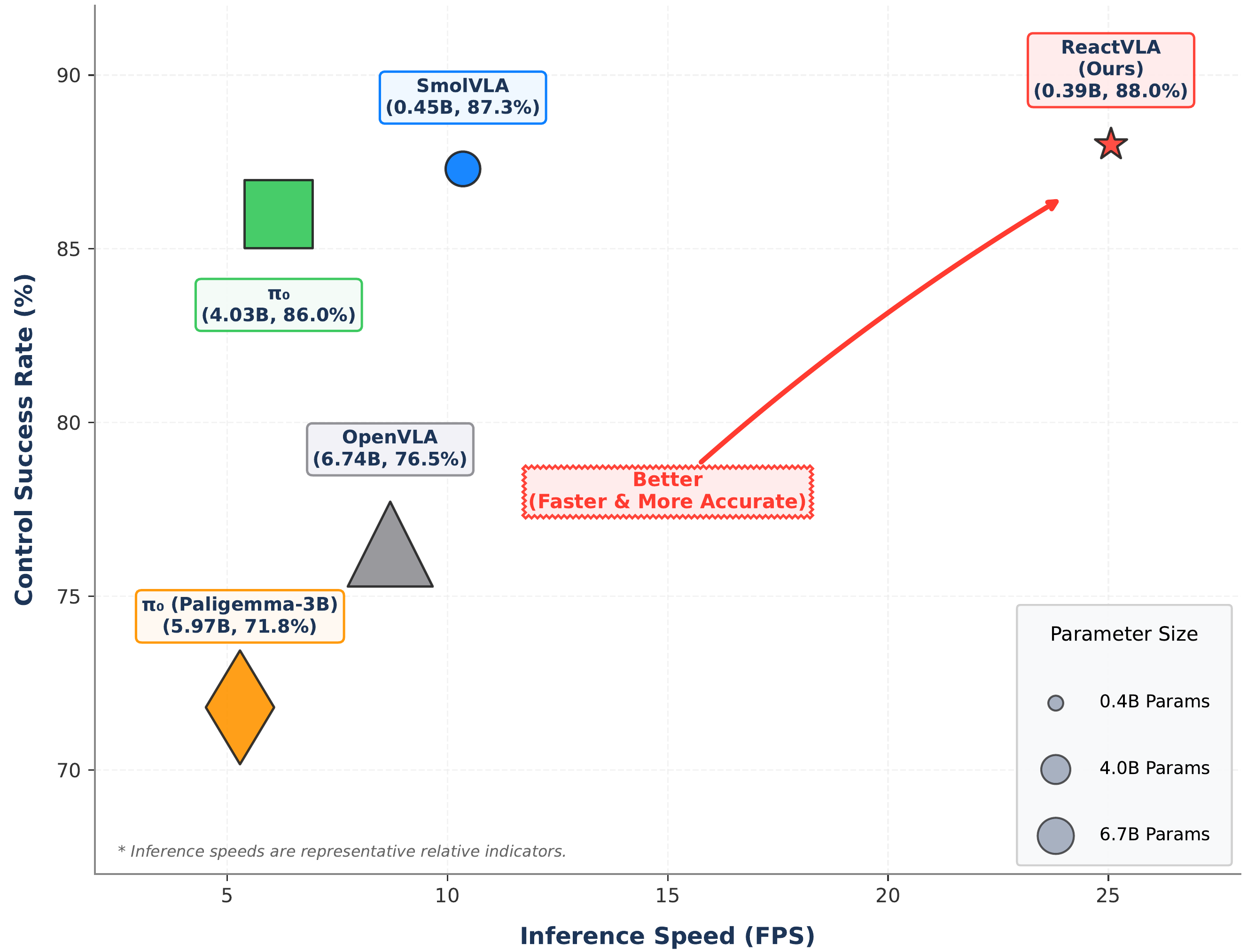
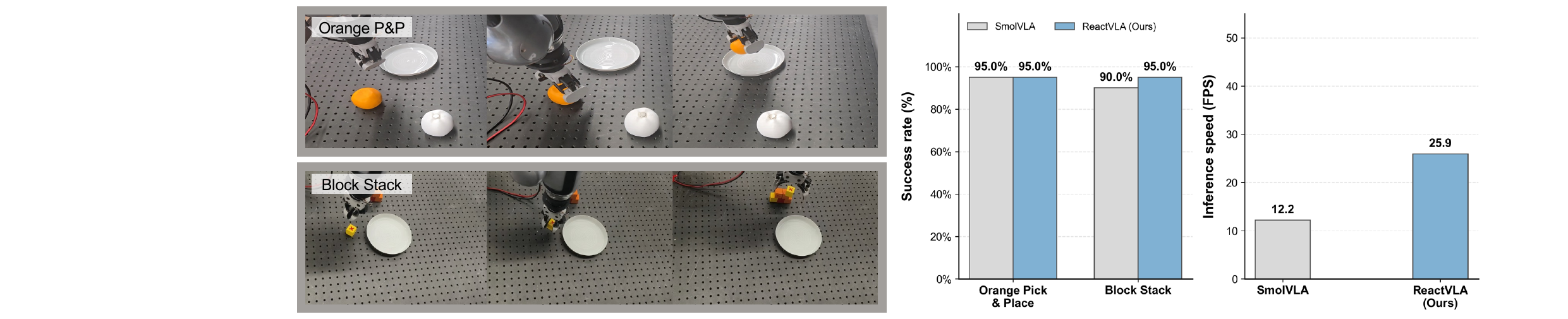
We evaluate ReactVLA on both large-scale simulation benchmarks (LIBERO and RoboIMI) and real-world robotic manipulation tasks. Experimental results show that ReactVLA consistently outperforms similarly sized VLA baselines, including SmolVLA and π0. On challenging precision manipulation tasks, ReactVLA achieves up to a 1.65× improvement in task performance while providing more than a 4× increase in inference speed compared with leading VLA models. These gains reduce policy latency to below 38.6 ms, enabling real-time reactive control for physical robot deployment.